


















































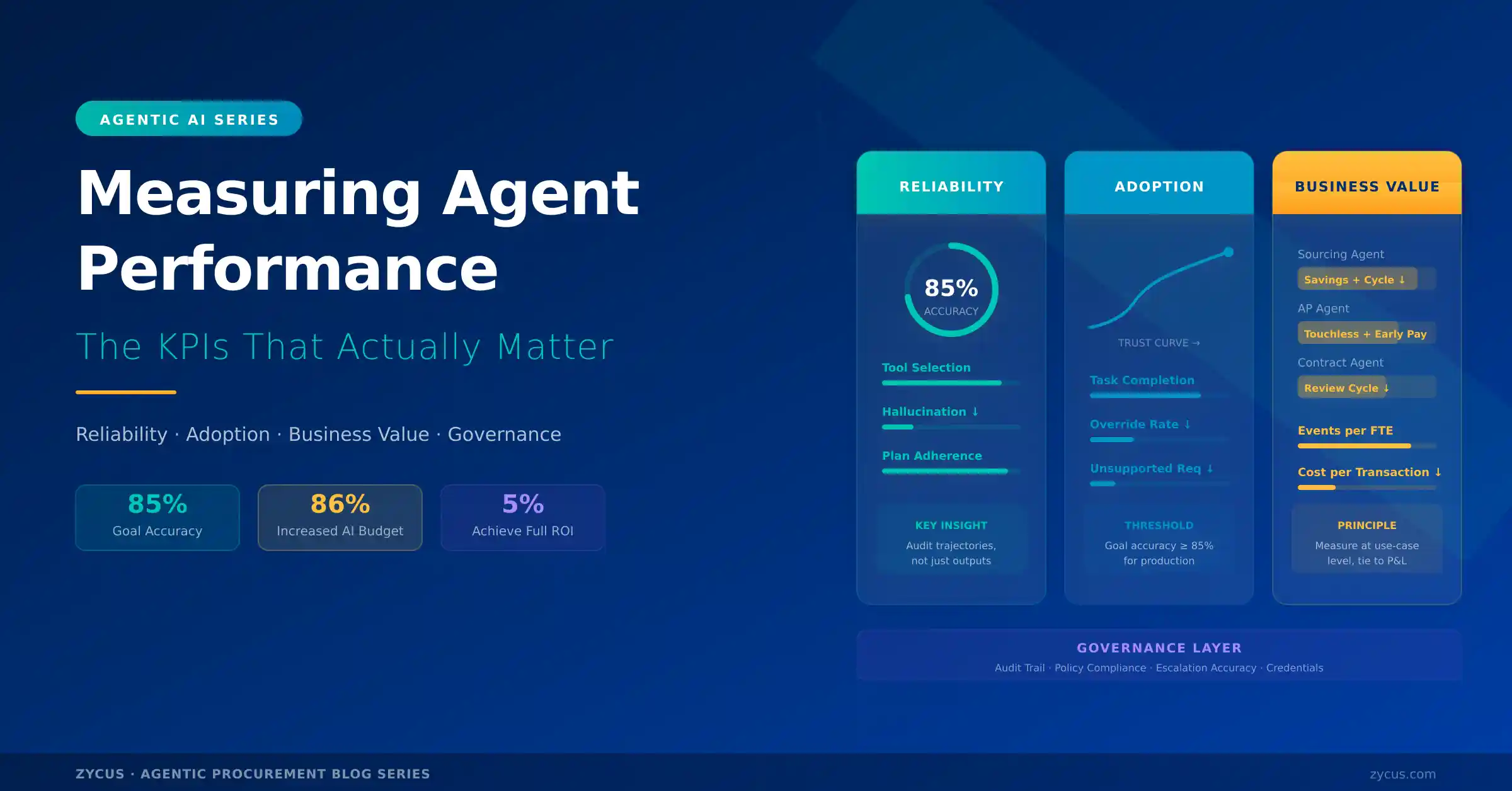

Deploying agentic AI is not the hard part. Knowing whether it is working is. Here is how to measure agent performance in procurement — with metrics the CFO will accept and the team can act on.
TL;DR
- 86% of enterprises increased AI budgets in 2025. Only 29% can measure the return and just 5% achieve substantial ROI. Without the right AI agent KPIs, pilots stall and budgets don’t scale.
- Agent KPIs fall into three categories: reliability (is it doing the right thing?), adoption (are people trusting it?), and business value (is the CFO seeing the number?). Google Cloud’s framework: audit trajectories, not just outputs.
- Production agents should hit 85%+ goal accuracy. Below 80% signals urgent attention. Human override rate should decrease over time — that is the trust curve.
- Leading indicators (override trend, unsupported request rate, plan adherence) predict agent success before results land. Lagging indicators (savings, cycle time) confirm it after.
- Governance metrics are not optional: audit trail completeness, policy violation rate, escalation accuracy. Gartner: AI regulation will cover 50% of economies by 2027, driving $5B in compliance investment.
- Companies with a formal AI change-management plan are 2.7× more likely to achieve ROI in the first 12 months. Measurement is the foundation of that plan.
Eighty-six percent of enterprises increased their AI budgets in 2025. Only 29% of executives say they can reliably measure the return. Industry benchmarks put the number even lower: only 5% of organizations achieve what researchers define as “substantial ROI” from AI — meaning the investment demonstrably improves the bottom line beyond total cost of implementation. The pressure is intensifying: . The measurement gap is not a minor inconvenience. It is the primary reason AI pilots do not scale, budgets do not expand, and procurement leaders cannot make the case to the board that agentic AI is delivering what it promised.
The problem is not a lack of data. It is a lack of the right metrics. Most organizations measure AI the same way they measure software: adoption rates, user logins, transaction volumes. Those metrics tell you the system is being used. They do not tell you whether the agent is making good decisions, improving over time, or creating value the CFO can verify. Agent performance requires a different measurement framework — one designed for systems that reason, act, and learn.
Download Whitepaper: The ROI of Source-to-Pay Transformation: How Smart Procurement Leaders Are Using AI to Deliver Real Value
Three Categories of Metrics that Matter
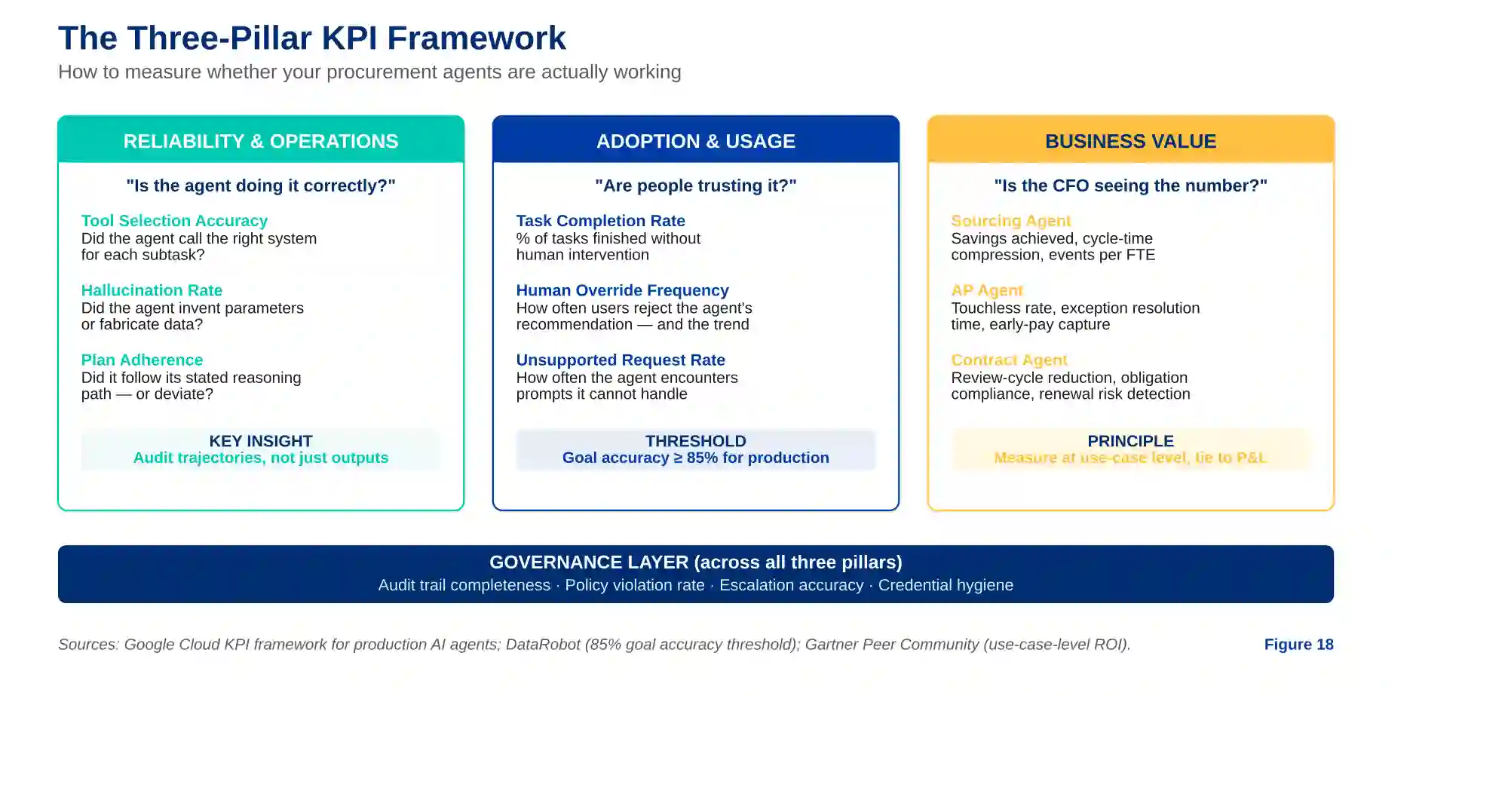
Google Cloud’s KPI framework for production AI agents offers the most coherent taxonomy available. It organizes agent metrics into three categories, and the framework translates directly to procurement:
The First Category is Reliability and Operational Performance
These metrics answer: “Is the agent doing what it is supposed to do, correctly?” The key measures are tool selection accuracy (did the agent call the right system for each subtask?), argument hallucination rate (did the agent invent parameters for a function call?), and plan adherence (did the agent follow the reasoning steps it outlined, or did it deviate?). Google’s critical insight: audit trajectories, not just outputs. An agent can produce the right answer through the wrong reasoning path — and that path will eventually fail on a novel input. In procurement, this means reviewing not just the award recommendation but the sourcing logic, the benchmark selection, and the supplier scoring that produced it.
The Second Category is Adoption and Usage
These metrics answer: “Are people actually using the agent, and are they trusting its outputs?” The measures here include task completion rate (what percentage of tasks does the agent finish without human intervention?), human override frequency (how often do users reject the agent’s recommendation?), and unsupported request rate (how often does the agent encounter a prompt it cannot handle?). DataRobot’s framework sets a clear threshold: goal accuracy should benchmark at 85% or higher for production agents, with anything below 80% signaling urgent attention. The override rate is particularly telling — if it is high, the agent is not trusted; if it decreases over time, the agent is learning and the team is calibrating.
The Third Category is Business Value
These metrics answer: “Is the agent creating measurable impact the CFO can verify?” The measures depend on the use case: sourcing agents are measured on savings achieved and cycle-time compression; AP agents on touchless processing rates and exception resolution time; contract agents on review-cycle reduction and obligation compliance; intake agents on requisition-to-PO time and maverick spend reduction. The Gartner Peer Community consensus on AI ROI measurement is direct: evaluate ROI at the use-case level, tied to the P&L. Start with the unit of value — per sourcing event, per invoice, per contract — and roll up. Isolate impact through control groups and before/after comparisons. Track both cash and non-cash benefits but prioritize cash conversion within twelve months.
Figure 1 — The three-pillar KPI framework: reliability, adoption, and business value — with governance underneath.
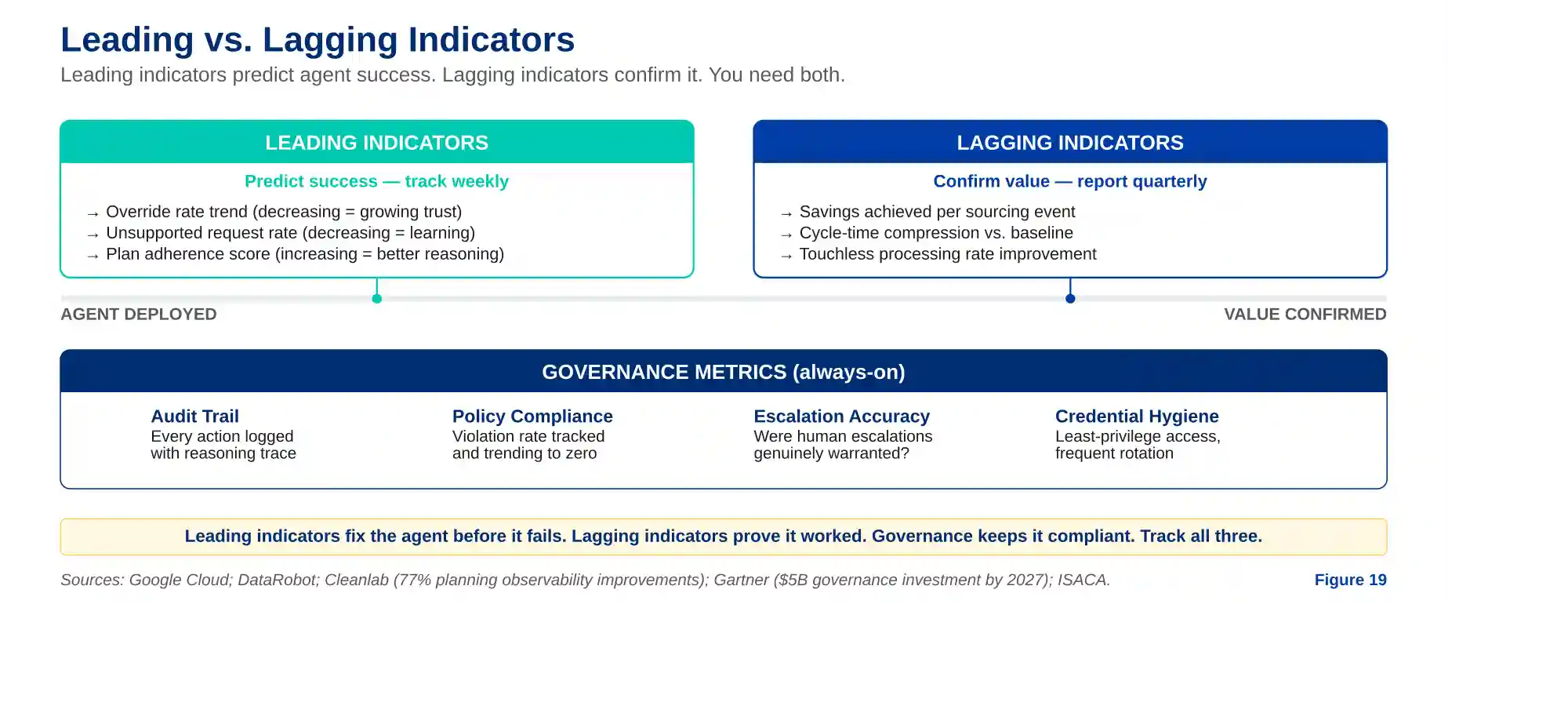
Leading Indicators vs. Lagging Indicators
The metrics above split naturally into two categories that procurement leaders should track differently. Lagging indicators — savings achieved, cycle-time compression, touchless rates — confirm that the agent created value after the fact. They are essential for board reporting and budget justification. But they arrive too late to fix a failing agent.
Leading indicators predict whether the agent will succeed before the results land. The most important leading indicators for procurement agents are: override rate trend (is it decreasing quarter over quarter, indicating growing trust and improving accuracy?), unsupported request rate (is the agent encountering fewer situations it cannot handle?), plan adherence score (is the agent following correct reasoning paths more consistently?), and tool-call success rate (is the agent selecting the right enterprise systems more reliably?). Cleanlab’s 2025 survey of engineering leaders found that 77% of enterprises plan to improve agent observability and evaluation in the next year — recognition that leading indicators are the gap most deployments have not yet filled.
Figure 2 — Leading vs. lagging indicators: leading predicts, lagging confirms, governance keeps it compliant.
The Governance Dimension
There is a third layer of measurement that most procurement teams overlook entirely: governance metrics. These do not measure whether the agent is effective. They measure whether it is operating within policy. As, driving an estimated $5 billion in AI-governance compliance investment, procurement teams that cannot demonstrate agent auditability will face regulatory exposure regardless of how much value the agents create.
The governance KPIs are straightforward: audit trail completeness (is every agent action logged with reasoning trace?), policy violation rate (how often does the agent act outside its defined guardrails?), escalation accuracy (when the agent surfaces a decision to a human, was the escalation warranted?), and credential hygiene (are agent service accounts following least-privilege principles with frequent rotation?). In procurement, this translates directly: can you show the auditor exactly why the agent selected Supplier B over Supplier A, which policy rules it applied, and what data it used? If the answer is no, the deployment has a governance gap that will eventually become a compliance incident. These are not glamorous metrics. They are the ones who keep the deployment running when the auditor arrives.
Capgemini’s 2025 research found that organizations with strong AI governance and readiness foundations achieve ROI 45% faster than their peers. Measurement is the foundation of that plan. Without it, the agent is a black box — trusted by some, doubted by others, defended by no one when the budget review arrives. Platforms built for measurability — Zycus’s Merlin Agentic Platform among them — embed audit trails, accuracy tracking, and business-value attribution into the agent architecture itself, so that every action the agent takes is traceable, every outcome is attributable, and every decision can be explained to the stakeholder who asks.
Hackett Group’s research frames the destination clearly: Digital World Class procurement teams deliver 2.6× greater ROI than peers, operate with 31% fewer FTEs, and run at 19% lower cost as a percentage of spend. They did not get there by deploying more agents. They got there by measuring the right things — and letting the measurement drive every deployment decision that followed.
The question is not whether your agents are running. It is whether you can prove they are working.
Related Reads:
- The Complete Guide to Agentic AI in Procurement
- eBook: Agentic AI in Procurement: A Comic Book Exploration
- Magazine: Intake to Outcomes (I2O) with Agentic AI-powered Procurement
- Why Agentic AI Is the Future of Source-to-Pay Automation by 2026
- AI Agents in Procurement: A Comprehensive Guide
- Watch Video: How Tata Play is Using AI Agents to Negotiate Real Business Deals
- Watch Video: Watch the Merlin AI Agents in Action: From Intake to Outcomes












