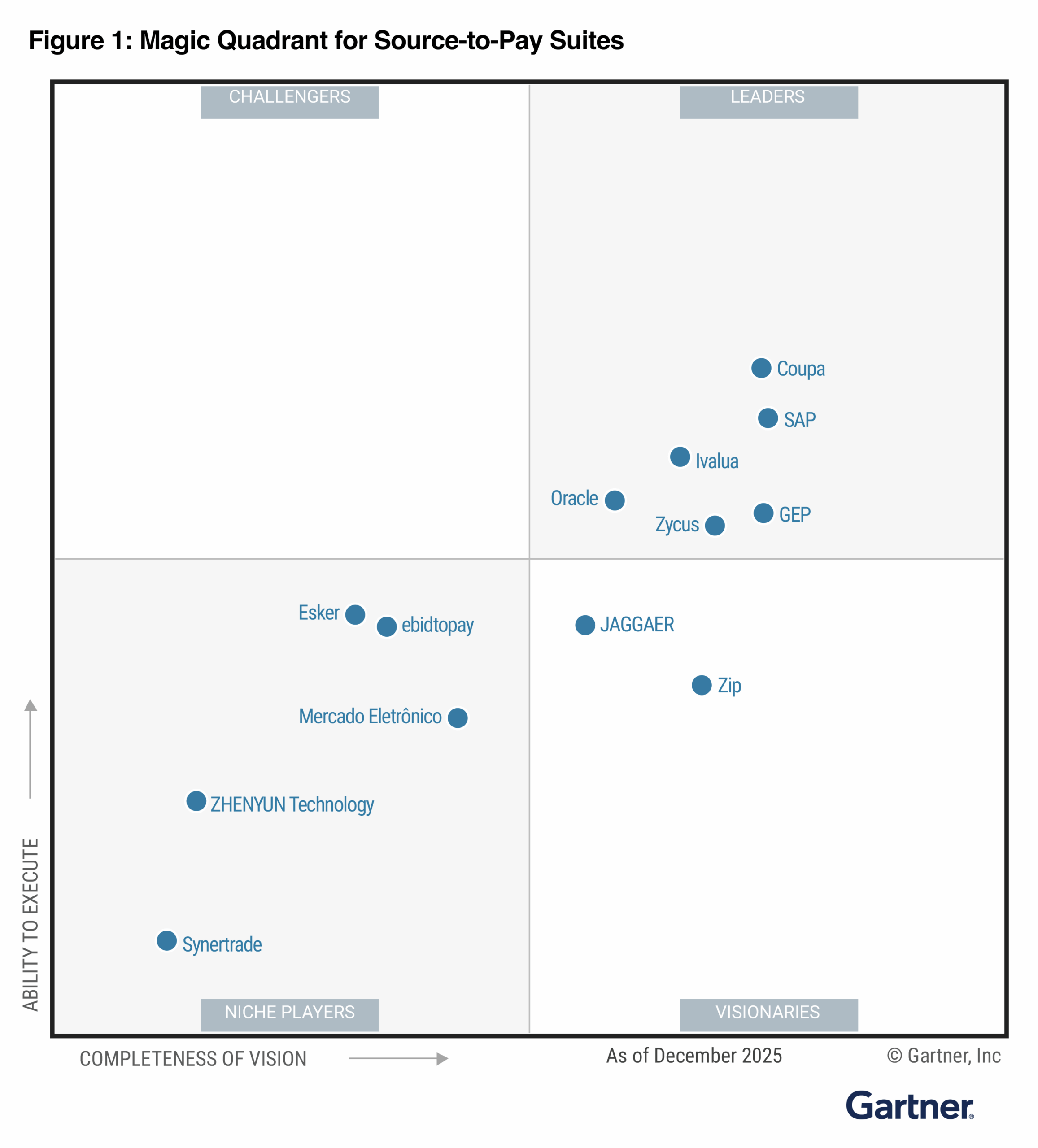
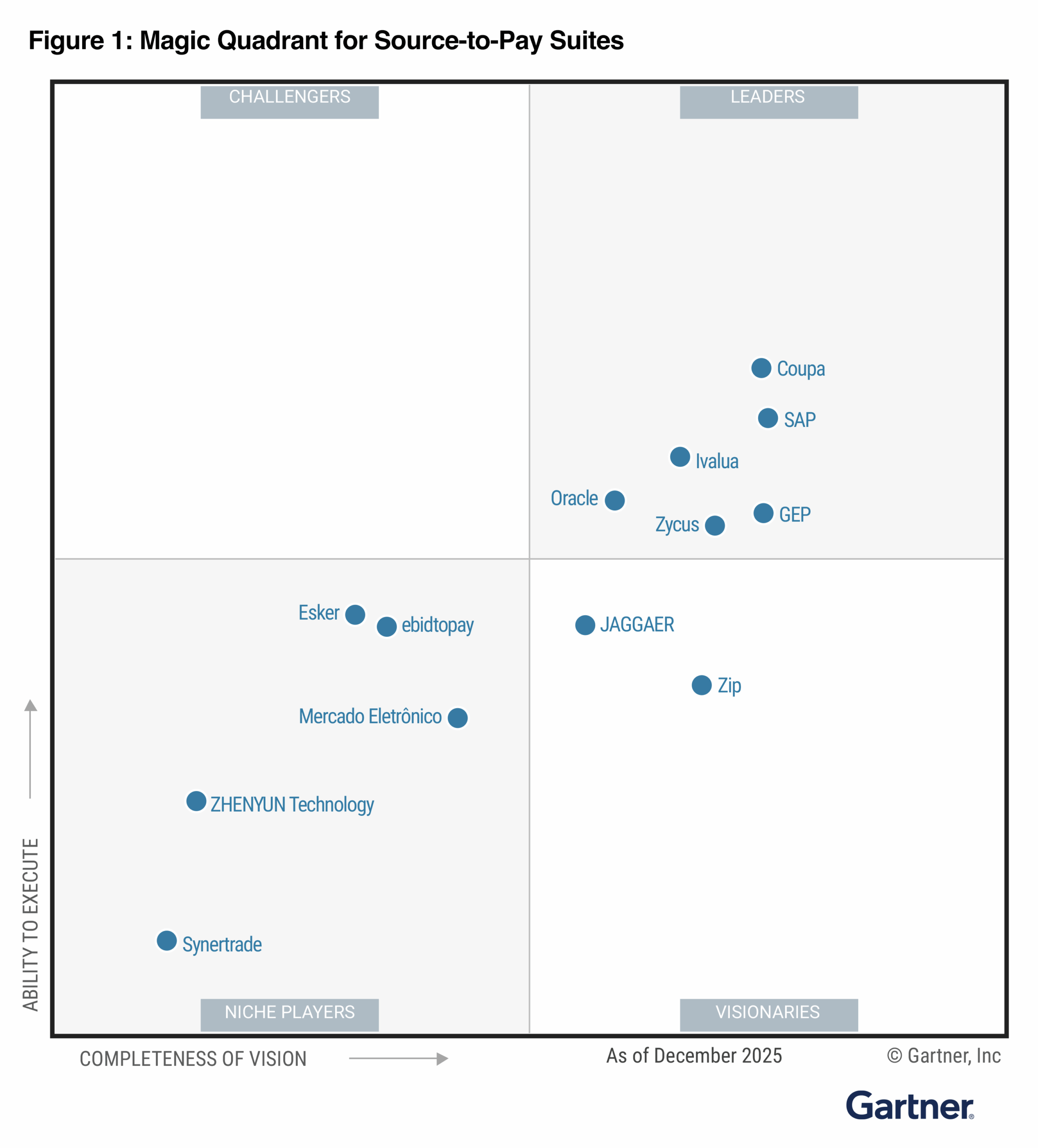
A Large Language Model (LLM) is a type of artificial intelligence system trained on vast quantities of text data to understand, generate, and analyze written language. LLMs learn statistical patterns across language at scale, enabling them to produce coherent text, answer questions, summarize documents, extract structured information, and reason across complex inputs. In procurement, LLMs are the underlying technology behind AI-powered tools for contract analysis, spend classification, supplier research, and document drafting.
Why Large Language Model (LLM) Matters in Procurement
Procurement generates enormous volumes of text contracts, RFx documents, supplier communications, and risk reports. LLMs can process and extract value from this content at a speed and scale that manual effort cannot match. As LLM capabilities are embedded in procurement platforms, they reduce contract review time, improve spend classification accuracy, and enable natural language data querying. Understanding what LLMs can and cannot do is increasingly important for teams evaluating AI-enabled tools.
The Core Process of Large Language Model (LLM)
- Pre-Training: An LLM is trained on large corpora of textbooks, websites, regulatory documents, technical papers — to develop a broad understanding of language structure, context, and meaning. This phase is computationally intensive and is performed by AI developers before any specific application is built on the model.
- Fine-Tuning and Adaptation: The general model is adapted for specific domains or tasks using targeted datasets. In procurement, this might involve fine-tuning on contract language, sourcing documents, or supplier data to improve accuracy on procurement-specific tasks such as clause extraction or category classification.
- Application Deployment: LLM capabilities are integrated into procurement tools — contract management platforms, spend analytics systems, or sourcing applications — where they surface as specific features: clause extraction, risk summarization, natural language search, or drafting assistance. Users interact with the application layer rather than the model directly.
- Output Review and Governance: LLM-generated outputs are reviewed by procurement professionals before decisions are made. Governance frameworks define which tasks can be automated versus which require human oversight, and audit trails record where AI-generated content was used in procurement decisions.
Core Components of Large Language Model (LLM)
- Training data quality determines the breadth and accuracy of the model’s knowledge. Models trained on diverse, high-quality text generalize better across tasks, while models fine-tuned on procurement-specific data perform more accurately on domain tasks.
- Context window is the amount of text an LLM can process in a single interaction. A large context window enables the model to analyze long contracts in full rather than in fragments that lose cross-document context.
- Prompt design shapes what the LLM produces. Well-constructed prompts that provide clear instructions, relevant context, and output format guidance significantly improve the quality and consistency of LLM outputs for procurement tasks.
- Hallucination risk management addresses the tendency of LLMs to generate plausible but factually incorrect outputs. Procurement applications must include validation workflows or retrieval-augmented generation to ground model outputs in verified source documents.
Key Benefits of Large Language Model (LLM)
- Accelerates contract review and abstraction by extracting key clauses, obligations, and dates from long documents at a fraction of the time required for manual review.
- Improves spend classification accuracy by applying language understanding to match transaction descriptions to taxonomy codes more precisely than rules-based systems.
- Enables natural language querying of procurement data, allowing category managers to interrogate spend and contract information without technical query skills.

Procurement Tasks Where LLMs Add the Most Value
- Contract clause extraction. Identifying and summarizing specific obligations, rights, dates, and risks across large contract portfolios — a task that scales poorly with manual effort.
- Supplier risk summarization. Synthesizing information from news, financial reports, and regulatory databases into structured risk profiles for category manager review.
- Spend data narrative generation. Converting structured spend analytics outputs into readable summaries and commentary for stakeholder reporting.
- RFx and SOW drafting. Generating first drafts of sourcing documents based on category inputs, prior event templates, and requirement descriptions.
KPIs of Large Language Model (LLM)
| Dimension | Sample KPIs |
| Accuracy | LLM output accuracy rate vs. human review baseline, error rate by task |
| Efficiency | Time saved per task, manual review rate for AI-assisted outputs |
| Adoption | % of applicable procurement tasks using LLM assistance |
| Governance | % of AI outputs reviewed before action, data privacy compliance rate |
Key Terms in Large Language Model (LLM)
- Foundation Model: A large-scale AI model trained on broad data that can be adapted for many tasks, of which LLMs are the most common type applied in procurement.
- Fine-Tuning: The process of further training a pre-built LLM on domain-specific data to improve its accuracy on targeted tasks.
- Hallucination: An LLM behavior in which the model generates factually incorrect or unsupported content presented with apparent confidence.
- Retrieval-Augmented Generation (RAG): A technique that combines LLM generation with real-time retrieval of source documents to ground outputs in verified content.
- Context Window: The maximum amount of text an LLM can process in a single interaction, which constrains the length of documents it can analyze at once.
Technology Enablement
Procurement platforms are embedding LLM capabilities into contract management, sourcing, and spend analytics modules. Organizations evaluating these features should assess model accuracy on procurement-specific content, data privacy commitments, and the governance framework governing when human review is required before AI-generated outputs are acted upon.
FAQs
Q1. What is a Large Language Model?
An AI system trained on vast text data to understand, generate, and analyze written language across a wide range of tasks.
Q2. How is an LLM different from a foundation model?
A foundation model is the broader category; LLMs are a specific type trained primarily on text. All LLMs are foundation models but not all foundation models are LLMs.
Q3. What procurement tasks are LLMs best suited to?
Contract extraction, spend classification, risk summarization, document drafting, and natural language data querying — tasks involving large volumes of text at a scale that manual effort cannot match.
Q4. What is AI hallucination and why does it matter for procurement?
Hallucination is when an LLM produces confident but incorrect outputs. In procurement this could mean inaccurate contract summaries or wrong risk assessments — making human review essential.
Q5. Will LLMs replace procurement professionals?
No. LLMs automate high-volume text processing tasks but cannot replicate the business judgment, relationship management, and strategic thinking that procurement professionals provide.
Q6. What data privacy risks do LLMs introduce?
Sending sensitive procurement documents to external LLM services may expose confidential data. Organizations must review data processing agreements and deployment architecture before use.
References
For further insights into these processes, explore Zycus’ dedicated resources related to Large Language Model (LLM):
- What are the Pitfalls to Avoid While Implementing Procurement Technology?
- Are You Making a Pointless Point in Procurement?
- The APIA Secret Sauce: Ingredients for a successful AP Transformation
- 6 imperatives for CPOs: Intent on driving business performance improvement
- AI Council: Leading AI-Driven Procurement Transformation